随着全球气候变化加剧和水利信息化建设的深入推进,水雨情数据的采集频率、覆盖范围和精细度呈指数级增长。如何高效处理这些海量、多源、异构的数据,实现实时计算分析、长期可靠存储与精准历史追溯,已成为现代水利行业数字化转型的核心挑战。本文将系统阐述水利业水雨情数据在数据处理与存储服务方面的关键技术架构与实践路径。
一、 海量数据存储:构建分层分级的弹性存储体系
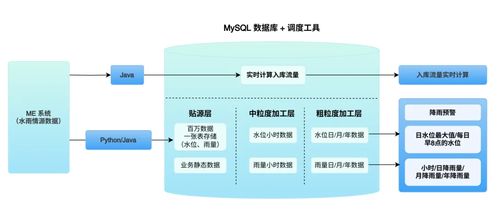
水利水雨情数据来源广泛,包括自动气象站、水文站、雷达、卫星遥感、视频监控等,具有数据体量大(TB/PB级)、产生速度快、格式多样(结构化、半结构化、非结构化)的特点。
- 混合存储架构:
- 热数据层:针对需要频繁访问和实时计算的近期高精度数据(如分钟级雨量、实时水位),采用高性能的分布式存储或全闪存阵列,保障低延迟读写。
- 温数据层:对于访问频率较低但需快速响应的历史数据(如过去数月的水情报表),可采用成本效益较高的分布式对象存储或云存储服务。
- 冷数据/归档层:对于用于长期追溯和法规遵从的多年甚至数十年的历史原始数据,采用磁带库、蓝光存储或低成本的云归档服务,在确保数据安全的前提下极大降低存储成本。
- 数据湖与数据仓库结合:构建以数据湖为核心的基础平台,原生存储所有原始数据,保留最大价值;根据业务主题(如洪水预报、水资源调度)建立数据仓库或数据湖仓,对清洗、治理后的数据进行高效建模与分析。
二、 实时计算与分析:打造流批一体的数据处理引擎
水雨情监测预警、防汛抗旱指挥等业务对数据的实时性要求极高,需在秒级或分钟级内完成数据汇聚、计算与决策支持。
- 流式计算框架:采用Apache Flink、Apache Storm或云厂商提供的流计算服务,对传感器、遥测终端上报的数据流进行实时处理。可实现:
- 实时聚合:如区域面雨量实时计算。
- 阈值告警:实时判断水位、雨量是否超警,并触发预警信息推送。
- 关联分析:实时关联雨情、水情、工情数据,进行综合研判。
- 批流一体化处理:统一的计算框架(如Flink)可同时处理实时流数据和历史批量数据,实现算法模型在实时预警与历史复盘中的一致应用,简化技术栈。
- 边缘计算赋能:在网络条件有限或对延迟极度敏感的关键站点(如水库、重要防洪断面),部署边缘计算节点,实现数据本地预处理、异常过滤和轻量级实时分析,减少中心平台压力并提升响应速度。
三、 长期追溯与数据治理:确保数据的可查、可信、可用
水雨情数据是水利科学研究、工程规划、灾害评估的宝贵资产,其长期保存的完整性、一致性与可追溯性至关重要。
- 全生命周期元数据管理:为每条数据建立贯穿采集、传输、处理、存储、使用、归档、销毁全过程的元数据档案,记录其来源、质量、版本、访问记录等,实现数据血缘追溯。
- 数据标准化与质量管控:制定统一的数据标准与编码体系,通过ETL/ELT流程进行自动化的数据清洗、校验、修补和质量评分,确保入库数据的一致性与可靠性。建立数据质量监控看板,对缺失、异常数据进行告警与跟踪处理。
- 不可篡改与安全归档:对关键原始数据和应用哈希算法、数字签名等技术,或利用区块链存证,确保其长期不可篡改。建立规范的归档策略与检索系统,使数十年的历史数据也能被快速、准确地定位和调用。
四、 数据处理与存储服务化:云原生与智能化演进
为应对业务灵活性和成本优化需求,数据处理与存储正朝着服务化、云原生方向发展。
- 云平台与混合云部署:利用公有云、私有云或混合云架构,按需获取弹性的计算与存储资源,避免一次性大规模硬件投入。云服务商提供的数据湖、数据仓库、流计算、AI平台等托管服务,能显著降低运维复杂度。
- 一体化数据服务平台:构建统一的数据中台或数据服务平台,将分散的数据存储、计算、治理、分析能力以API或服务的形式提供给前端业务应用(如智慧水利大脑、移动APP),实现数据资产的集约化管理和价值高效释放。
- AI驱动的智能管理:引入机器学习算法,用于数据异常自动检测、存储策略智能优化(自动冷热分层)、计算资源动态调度等,提升系统自动化与智能化水平。
###
水利业水雨情数据的“存、算、溯”是一个系统性工程。通过构建分层弹性存储体系、流批一体计算引擎、完善的数据治理框架,并拥抱云原生与服务化技术,能够有效应对数据规模与业务复杂度的双重挑战。最终目标是形成覆盖数据全生命周期的智能化管理能力,让海量水雨情数据不仅存得下、算得快、查得到,更能用得好,为水旱灾害防御、水资源优化配置、水生态保护修复提供坚实可靠的数据基石,赋能水利高质量发展与现代化进程。